A PubSearch-ről
A bejegyzés nagyobb része 2013. februárjában írodott, 2018-ban aktualizáltam.
Történet
Ez a program volt a szakdolgozatom az egyetemen és egyben az első interneten publikált projektem. Létrehoztam hozzá egy SourceForge projektet, hogy SVN-t tudjak használni, meg legyen wiki-m, ahol a terveket szövöm.
Egy évvel a projekt elkezdése után, amikor már jó pár hónapja megvolt az v1.0, 2013 első heteiben kaptam egy levelet a Softpedia-tól, melyben arról tájékoztattak, hogy a programomat felvették a szoftveradatbázisukba.
4 órán belül 14-en letöltötték, ez akkor egy kis löketet adott, hogy továbbfejlesszem a programot. Nagy vonalakban megterveztem a PubSearch 2-t, de az implementáció sajnos elsikkadt a többi teendőm között.
A Softpedia-ról pár évvel később lekerült a programom, talán azért, mert időközben haszontalanná vált a frissítéseim nélkül.
Mi is ez?
Ez egy Java program, amivel több publikációs adatbázisban kereshetsz (mint például Google Scholar, CiteSeerX, ACM, SpringerLink). Beírod a szerző nevét és a PubSearch összegyűjti ezen szerző publikációinak alapvető információit. Képes letölteni tranzitívan a hivatkozó publikációk listáját is, tehát egy kutató használhatja a programot impakt faktorának kiszámításához.
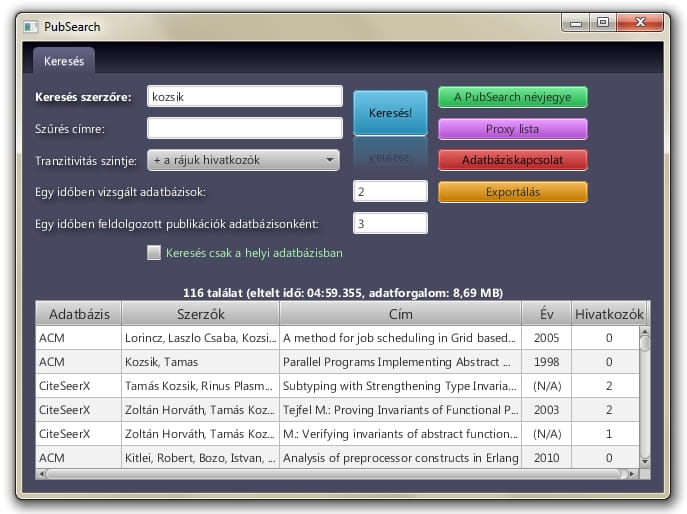
A program proxy listát használ a weboldalak elérésére, hogy elkerülje a sorozatos lekérdezésekből adódó esetleges tiltást. Az adatbázisok bejárási módját a program definíciós fájlokból olvassa ki, melyet egyszerű szövegszerkesztővel lehet készíteni vagy módosítani. A publikációk adatait exportálhatod könyvtári formátumokban.
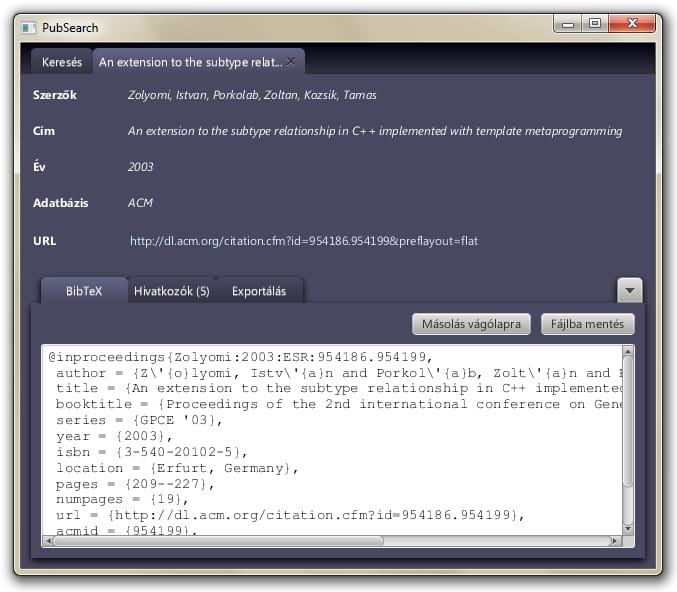
JRE, MySQL és egy proxy lista szükséges a futtatásához.
Funkciók
Mivel a publikációs adatbázisok weboldalai megváltoztak mióta utoljára ezzel foglalkoztam, a program jelenleg nem sok eredményt tud listázni.
- a következő publikációs adatbázisokban keres:
- hozzáadhatsz/módosíthatod az adatbázis definíciós fájlokat
- automatikus proxy lista letöltés
- hivatkozó publikációk listájának tranzitív bejárása (ahol lehetséges)
- az adatokat MySQL adatbázisban tárolja
- az eredmény táblázat exportálható CSV vagy könyvtári formátumban
- az egyes publikációk adatai exportálhatóak könyvtári formátumban
- hozzáadhatsz/módosíthatod a könyvtári formátum sablonokat
- magyar és angol grafikus felület
Linkek
Továbbfejlesztési ötletek
- Még 2013 év elején nagy vonalakban megterveztem a PubSearch 2-t, melynek lényege a modularitás. A cél az, hogy univerzálisabb legyen a program. A publikációs adatbázisok oldalai folyamatosan változnak, és habár a PubSearch 1.x definíciós fájljait könnyű aktualizálni, bizonyos adatokat, funkciókat ezeken a site-okon már nem lehet a beégetett, egységes algoritmussal elérni. Ezért lehetőséget kéne biztosítani moduláris bővítésre, egy Java interfészen keresztül. Így specializált crawlereket lehetne hozzáadni a programhoz, JAR fájlokban, amiket a program betöltene induláskor. És persze magát a PubSearch 1.x-et egy beégetett crawlerként továbbra is lehetne használni.
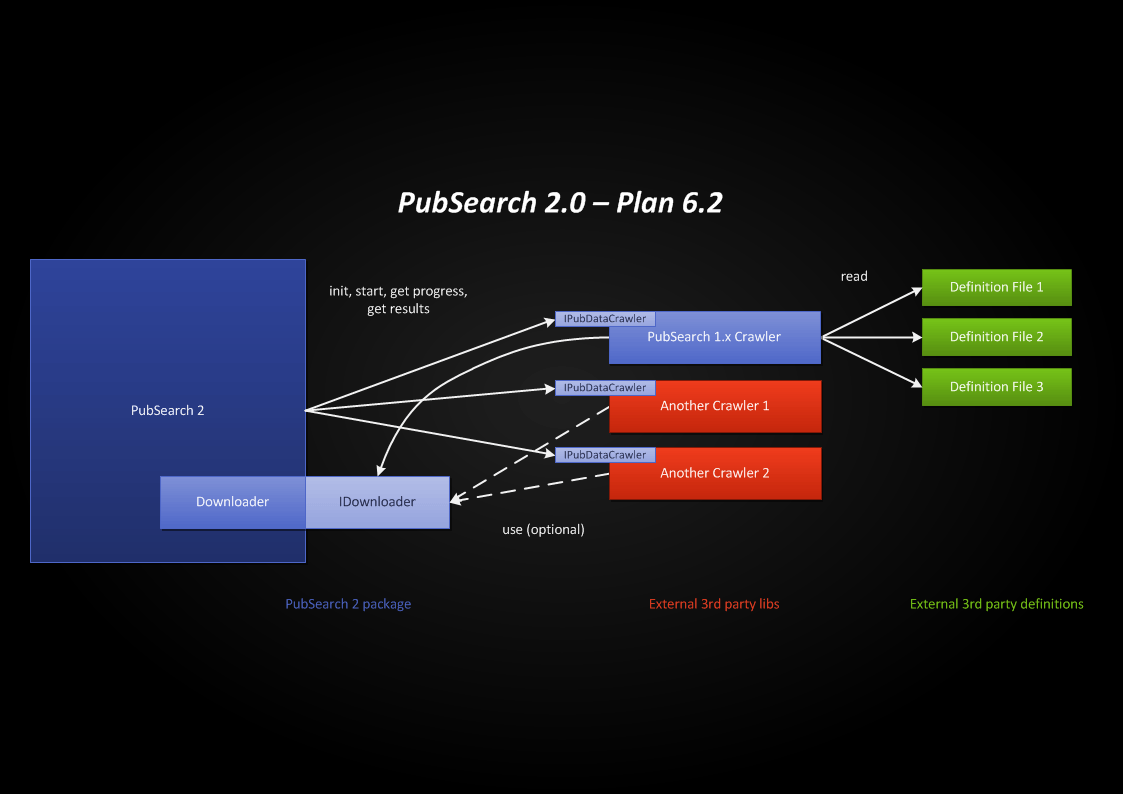
- Több beállítási lehetőség is jól jönne a programba, pl. publikációs adatbázisok kiválasztása, konfigurálható proxy kezelés.
- A HTML parszolást is elegánsabbá kéne tenni. Anno jobb ötlet híján reguláris kifejezésekkel parszoltam, ami mint tudjuk, nem egészséges.
- Jó lenne publikáció merge funkció is, amennyire lehet automatizáltan.