About PubSearch
Most of this post was written in 2013, but I actualized it in 2018.
History
This program was my thesis at university and this was my first project that I’ve ever published on the web. I created a SourceForge project to be able to use SVN and write wiki pages where I can do the planning.
A year after I started developing the program, and months after v1.0, in the beginning of 2013, Softpedia wrote me an email informing me that they had included my program in their public software database.
It was downloaded 14 times within 4 hours, and this gave me a little motivation to continue developing the project. I roughly planned PubSearch 2, but among my other tasks, sadly I had no time to implement it.
A few years later the program disappeared from Softpedia, maybe because without my updates it became useless.
What’s this?
This is a Java tool which can search in multiple publication databases (such as Google Scholar, CiteSeerX, ACM, SpringerLink). You type the author’s name and PubSearch grabs the basic information of her/his publications. It can transitively crawl the “cited-by” lists, so a researcher can use this tool for calculating her/his impact factor.
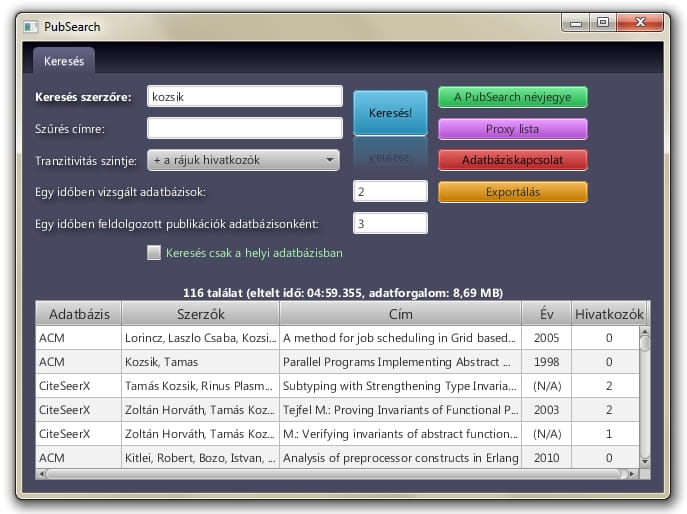
It uses a proxy list to reach those sites, to avoid banning because of the heavy network traffic. The program uses definition files to crawl the databases, you can edit these with any simple text editor or add your own definiton. You can export publication data in citation formats.
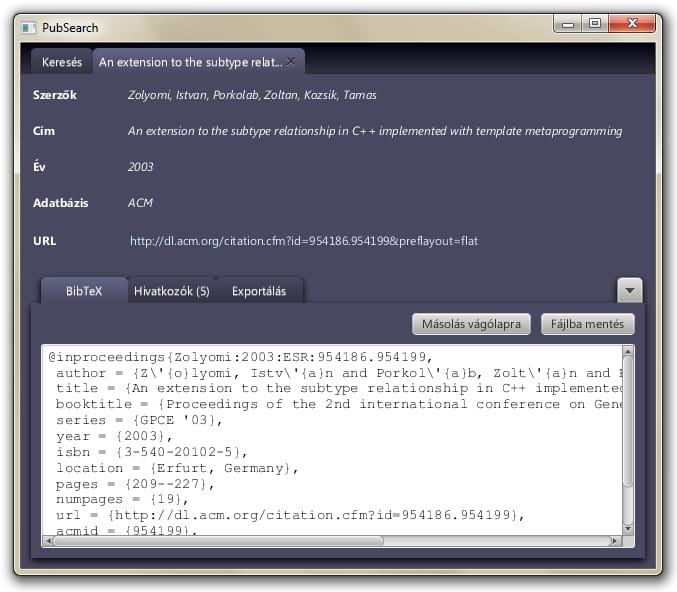
JRE, MySQL and a proxy list is required to run the program.
Features
Websites of publication databases are changed since I last updated this project, so the program may only list a few results or none.
- searches in the following databases:
- you can edit/add publication database definitions
- automatic proxy list downloading
- crawl cited by publications transitively (where possible)
- publication data stored in a MySQL database
- export results table in CSV or citation format
- export individual publication data in citation format
- you can edit/add citation format templates
- hungarian and english GUI
Links
Ideas for further development
In the beginning of 2013, I roughly planned PubSearch 2, with modularity in mind. The goal is to make it more universal. Websites of publication databases are continuously changing, and altough PubSearch 1.x can be easily actualized, some features of these websites cannot be reached by the built-in uniform algorithm of PubSearch 1.x. So modularity should be provided, through a Java interface. This way specialized crawlers can be added as JAR files, which can be loaded when the program starts. And of course, PubSearch 1.x would be still there as a built-in crawler.
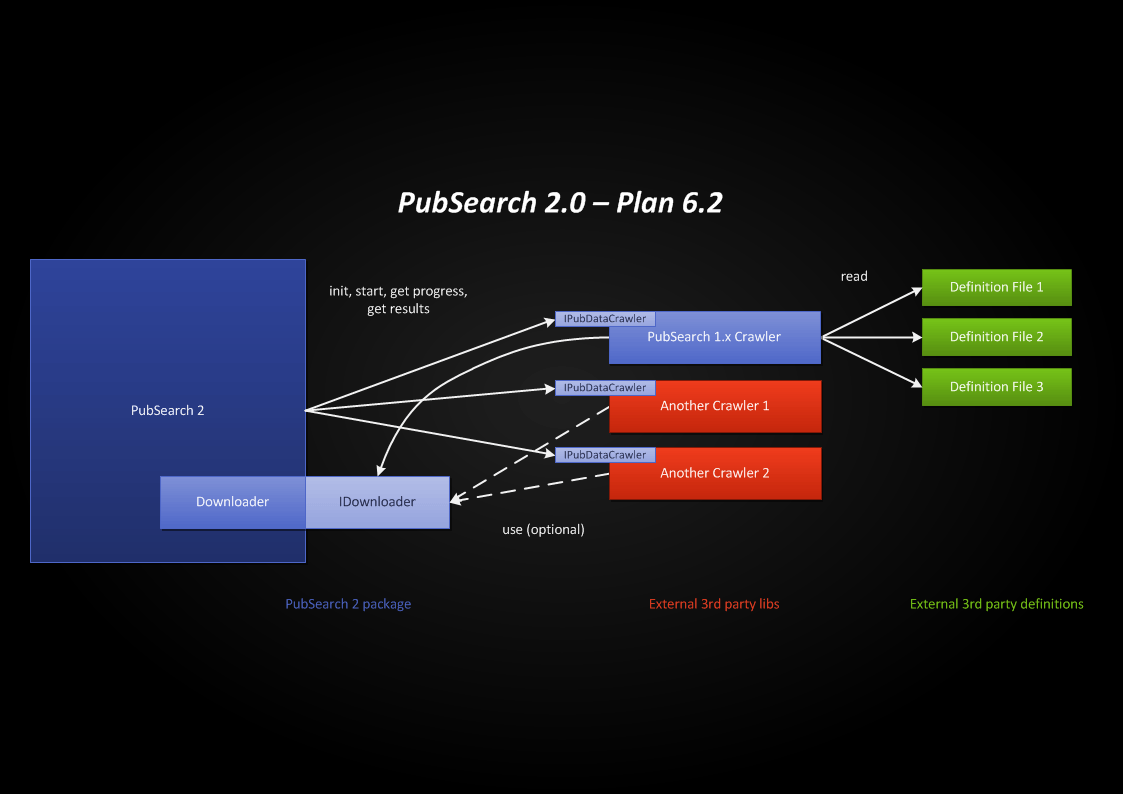
Would be nice to add more settings, like selecting publication databases or crawlers, and managing proxy lists.
HTML parsing should be much more elegant. Back then, without any better ideas, I used regular expressions, which as we know is not a proper approach.
Merging publications would be also great, even automatized as much as it can be.